Columnist Patrick Stox provides some dos and don'ts for creating your robots.txt file -- along with examples of companies who have gotten creative with their files.

One of the most boring topics in technical SEO is robots.txt. Rarely is there an interesting problem needing to be solved in the file, and most errors come from not understanding the directives or from typos. The general purpose of a robots.txt file is simply to suggest to crawlers where they can and cannot go.
Basic parts of the robots.txt file
- User-agent — specifies which robot.
- Disallow — suggests the robots not crawl this area.
- Allow — allows robots to crawl this area.
- Crawl-delay — tells robots to wait a certain number of seconds before continuing the crawl.
- Sitemap — specifies the sitemap location.
- Noindex — tells Google to remove pages from the index.
- # — comments out a line so it will not be read.
- * — match any text.
- $ — the URL must end here.
Other things you should know about robots.txt
- Robots.txt must be in the main folder, i.e., domain.com/robots.txt.
- Each subdomain needs its own robots.txt — www.domain.com/robots.txt is not the same as domain.com/robots.txt.
- Crawlers can ignore robots.txt.
- URLs and the robots.txt file are case-sensitive.
- Disallow simply suggests crawlers not go to a location. Many people use this to try to de-index pages, but it won’t work. If someone links to a page externally, it will still be shown in the SERPs.
- Crawl-delay is not honored by Google, but you can manage crawl settings in Google Search Console.
- Allow CSS and JS, according to Google’s Gary Illyes:
User-Agent: Googlebot
Allow: .js
Allow: .css
- Validate your robots.txt file in Google Search Console and Bing Webmaster Tools.
- Noindex will work, according to Eric Enge of Stone Temple Consulting, but Google Webmaster Trends Analyst John Mueller recommends against using it. It’s better to noindex via meta robots or x-robots.
- Don’t block crawling to avoid duplicate content. Read more about how Google consolidates signals around duplicate content.
- Don’t disallow pages which are redirected. The spiders won’t be able to follow the redirect.
- Disallowing pages prevents previous versions from being shown in archive.org.
- You can search archive.org for older versions of robots.txt — just type in the URL, i.e., domain.com/robots.txt.
- The max size for a robots.txt file is 500 KB.
Now for the fun stuff!
Many companies have done creative things with their robots.txt files. Take a look at the following examples!
ASCII art and job openings
Nike.com has a nice take on their slogan inside their robots.txt, “just crawl it” but they also included their logo.
Seer also uses art and has a recruitment message.

TripAdvisor has a recruitment message right in the robots.txt file.
Fun robots
Yelp likes to remin the robots that Asimov’s Three Laws are in effect.

As does last.fm.

According to YouTube, we already lost the war to robots.

Page One Power has a nice “Star Wars” reference in their robots.txt.
Google wants to make sure Larry Page and Sergey Brin are safe from Terminators in their killer-robots.txt file.

Who can ignore the front page of the internet? Reddit references Bender from “Futurama” and Gort from “The Day The Earth Stood Still.”

Humans.txt?
Humans.txt describes themselves as “an initiative for knowing the people behind a website. It’s a TXT file that contains information about the different people who have contributed to building the website.” I was surprised to see this more often than I would have thought when I tried on a few domains. Check out https://www.google.com/humans.txt.
Just using robots.txt to mess with people at this point
One of my favorite examples is from Oliver Mason, who disallows everything and bids his blog farewell, only to then allow every individual file again farther down in the file. As he comments at the bottom, he knows this is a bad idea. (Don’t just read the robots.txt here, seriously, go read this guy’s whole website.)
On my personal website, I have a robots.txt file to mess with people as well. The file validates fine, even though at first glance it would look like I’m blocking all crawlers.
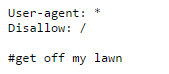
The reason is that I saved the file with a BOM (byte order mark) character at the beginning, which makes my first line invalid — as you can see when I go to verify in Google Search Console. With the first line invalid, the Disallow has no User-Agent reference, so it is also invalid.
Indexed pages that shouldn’t exist
If you search for “World’s Greatest SEO,” you’ll find a page on Matt Cutts’ website that doesn’t actually exist. SEO Mofo chose a directory (/files) that is blocked by https://www.mattcutts.com/robots.txt. The only information Google has about this page is from the links that were built to the non-existent page. While the page 404s, Google still shows it in the search results with the anchor text from the links.

A whole freaking website inside robots.txt
Thought up by Alec Bertram, this amazing feat is chronicled where else but his robots.txt file. He has the how, the source and even a menu to guide you.
This was also used on vinna.cc to embed an entire game into the file. Head over to https://vinna.cc/robots.txt and play Robots Robots Revolution!

Some opinions expressed in this article may be those of a guest author and not necessarily Search Engine Land. Staff authors are listed here.
To know more latest update or tips about Search Engine Optimization (SEO), Search Engine Marketing (SEM) - Fill ContactUs Form or call at +44 2032892236 or Email us at - adviser.illusiongroups@gmail.com
No comments:
Post a Comment